In my last post I showed that Blackbox’s logging behaviour when writing to an onboard flash chip ends up adding a lot of variance to the looptime. This was because 3/4 of the time, Blackbox would just write its log entry to a write buffer in memory, which was very fast, but the remaining 1/4 of the time it would have to flush that buffer through to the flash chip itself, which was very slow. The difference in speed between these iterations causes a variance in the looptime which is undesirable for stable flight. This caused the distribution of overhead due to Blackbox logging to have a twin-peaked shape like this:
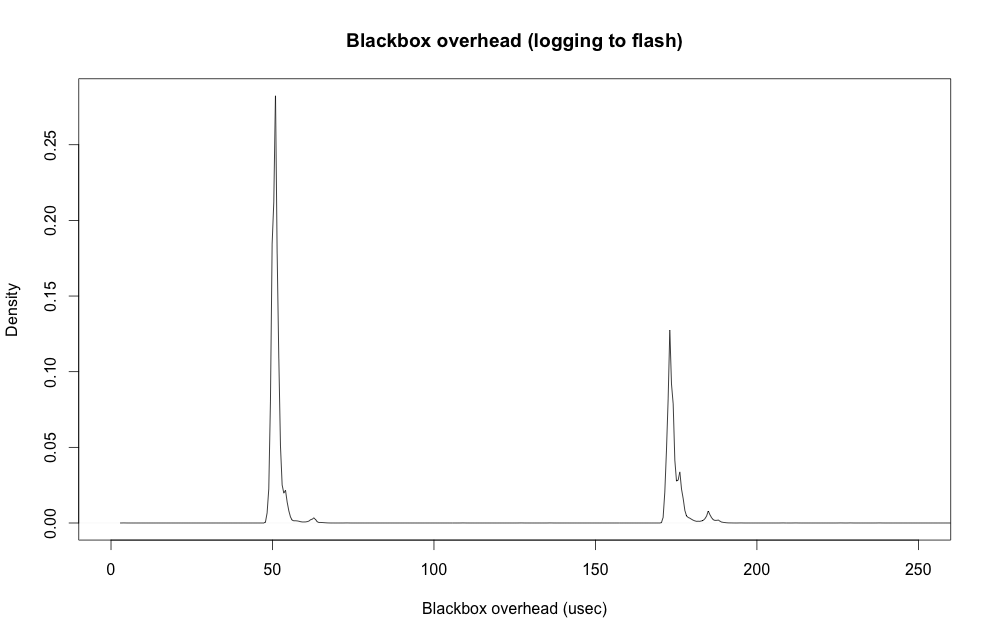
One way of solving this problem is to use the CPU’s DMA controller to send the write buffer out to the flash in the background. This way the buffer can be slowly written to the flash chip all the time while other tasks are executing, instead of the whole CPU pausing to make one big slow write every now and then. That’s still something I want to implement in the future, but in the meantime I looked into other ways to reduce the variance.
Since I want every Blackbox logging iteration to take a similar amount of time, I need to perform similar tasks in every iteration. So flushing the buffer to the flash in only 1 in 4 iterations is a big no-no. Instead I decided to flush the buffer out to the flash in every iteration, even if the buffer wasn’t full yet. This increases the mean execution time a little bit, because each flush operation itself has some overhead, but it causes a dramatic improvement in the standard deviation. Instead of two widely-spaced peaks in execution time, there is now one large, tightly-grouped peak:
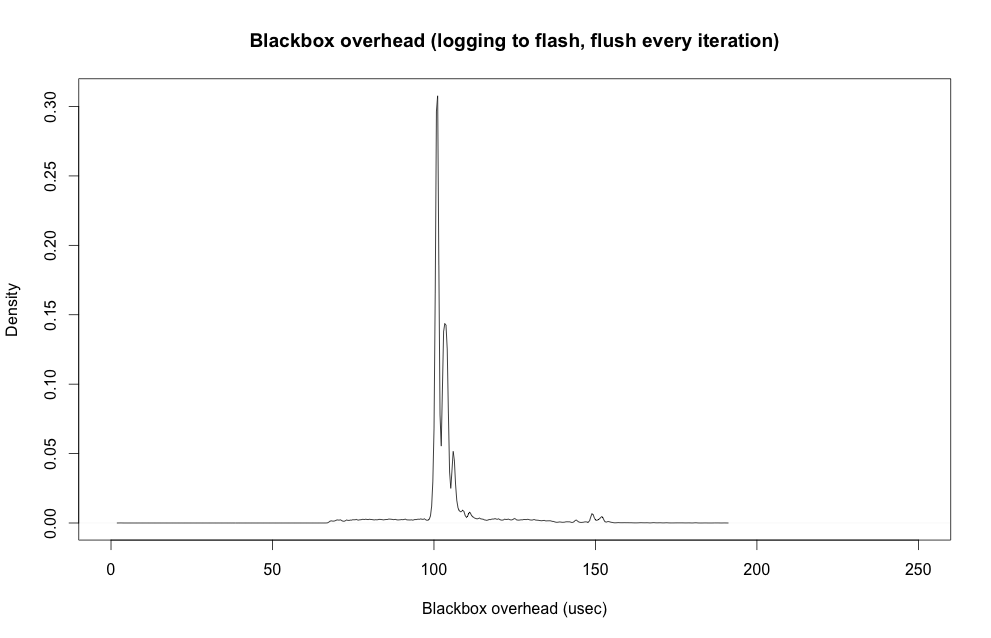
Here’s the new statistics:
|
Mean overhead (μs) |
Standard deviation (μs) | |
| Logging to serial | 64 | 5 |
| Logging to flash (old behaviour) |
95 | 59 |
|
Logging to flash |
104 | 11 |
Flushing every iteration only causes a modest 9% increase in mean logging overhead, while it reduces the standard deviation by 81%!
This fix will be part of the next release of Cleanflight (the current release as of this writing is 1.9).